Cómo elegir los mejores modelos de machine learning en riesgo crediticio
Octubre 3, 2024 – Producto
La creciente adopción de la digitalización financiera, impulsada por tecnologías como la IA y el Machine Learning, está transformando la manera en que las instituciones gestionan sus operaciones y la forma en que los clientes interactúan con los servicios financieros.
Las predicciones de PwC indican que
la IA podría sumar hasta 15.7% del PIB global para 2030.
La evaluación
crediticia, un pilar fundamental en el sector financiero, hace uso del machine learning para analizar
grandes volúmenes de datos, identificando patrones complejos. Sin embargo, la implementación exitosa de modelos de
machine learning en este ámbito requiere una cuidadosa evaluación y selección.
Según un informe de McKinsey & Company, el uso de Machine Learning en servicios financieros puede mejorar la exactitud de las decisiones crediticias hasta en un 35%, disminuyendo las tasas de morosidad en un 30%.
En este artículo, exploraremos el estado actual del Open Finance en los principales países de LATAM, desglosando los avances, retos y perspectivas de Brasil, México, Colombia, Chile, Argentina y Perú, basando la investigación primordialmente en “Banca Abierta en Latinoamérica”, estudio realizado por Mastercard en conjunto con la consultora estadounidense Gartner.
Si bien los modelos estadísticos tradicionales, como el análisis discriminante y la regresión logística, han sido pilares en la evaluación del riesgo crediticio, la creciente complejidad de los datos y la necesidad de modelos más precisos han impulsado la búsqueda de alternativas para capturar patrones no lineales y de alta dimensionalidad.
La irrupción del machine learning, con algoritmos como Random Forest y Support Vector Machines, ha ofrecido una mayor flexibilidad y capacidad predictiva. Sin embargo, es el deep learning, con sus redes neuronales profundas, que permite extraer información de datos altamente estructurados y no estructurados.
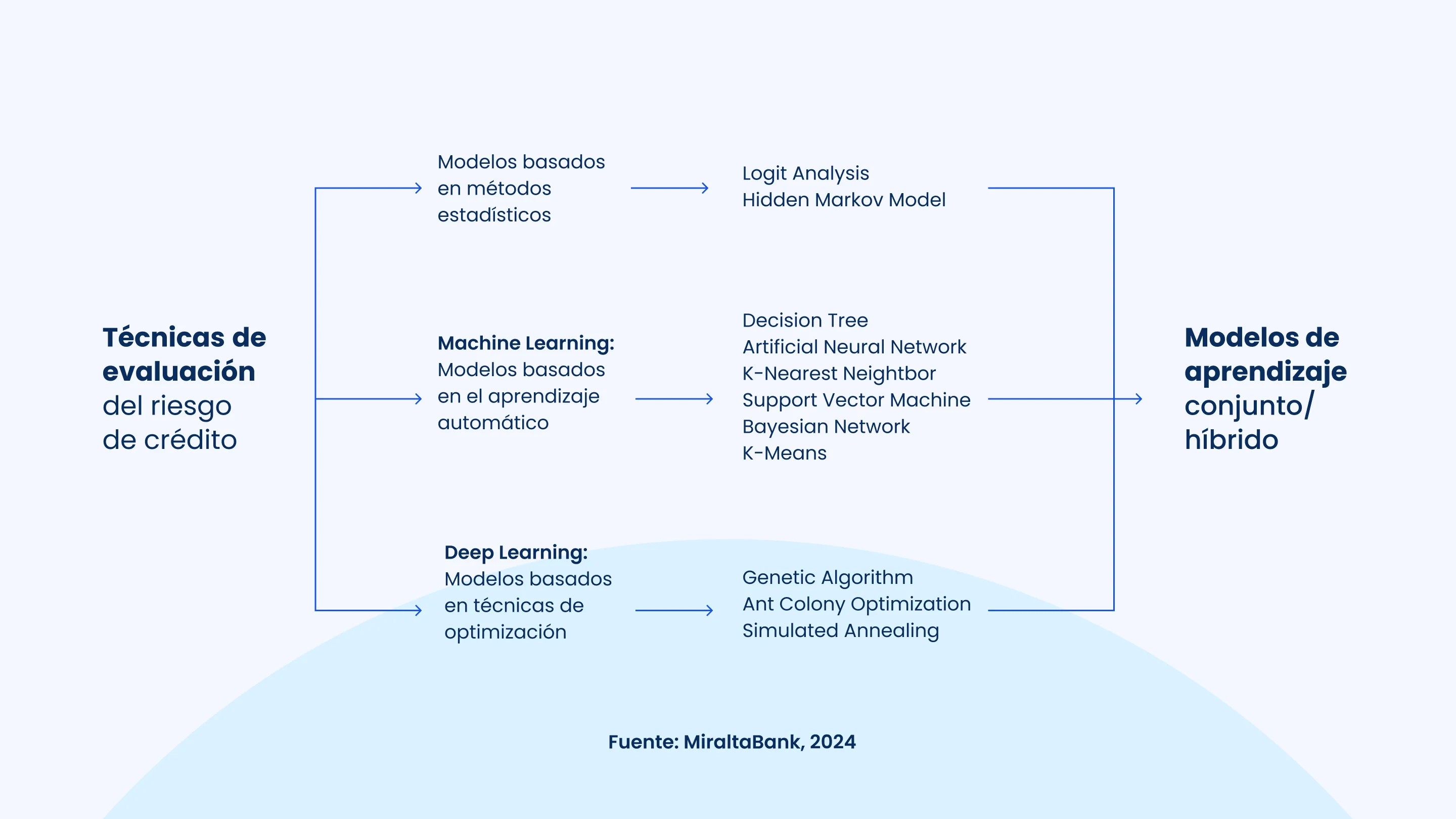
Modelos de Machine Learning para evaluación y riesgo crediticio
De acuerdo a un análisis de Data credit risk: A systemic review, el desarrollo y selección de modelos de machine learning para la evaluación crediticia incluye varias etapas clave: preparación de datos (limpieza, transformación y balanceo), selección de algoritmos adecuados (regresión logística, árboles de decisión, random forest, XGBoost, redes neuronales), entrenamiento y ajuste de hiperparámetros, evaluación del desempeño con métricas como precisión y F1-score, validación cruzada y backtesting. El modelo final se elige según su desempeño, interpretabilidad y complejidad.
A continuación, se presenta un resumen conciso de los modelos de machine learning más utilizados para aprender patrones complejos, a partir de grandes volúmenes de datos:
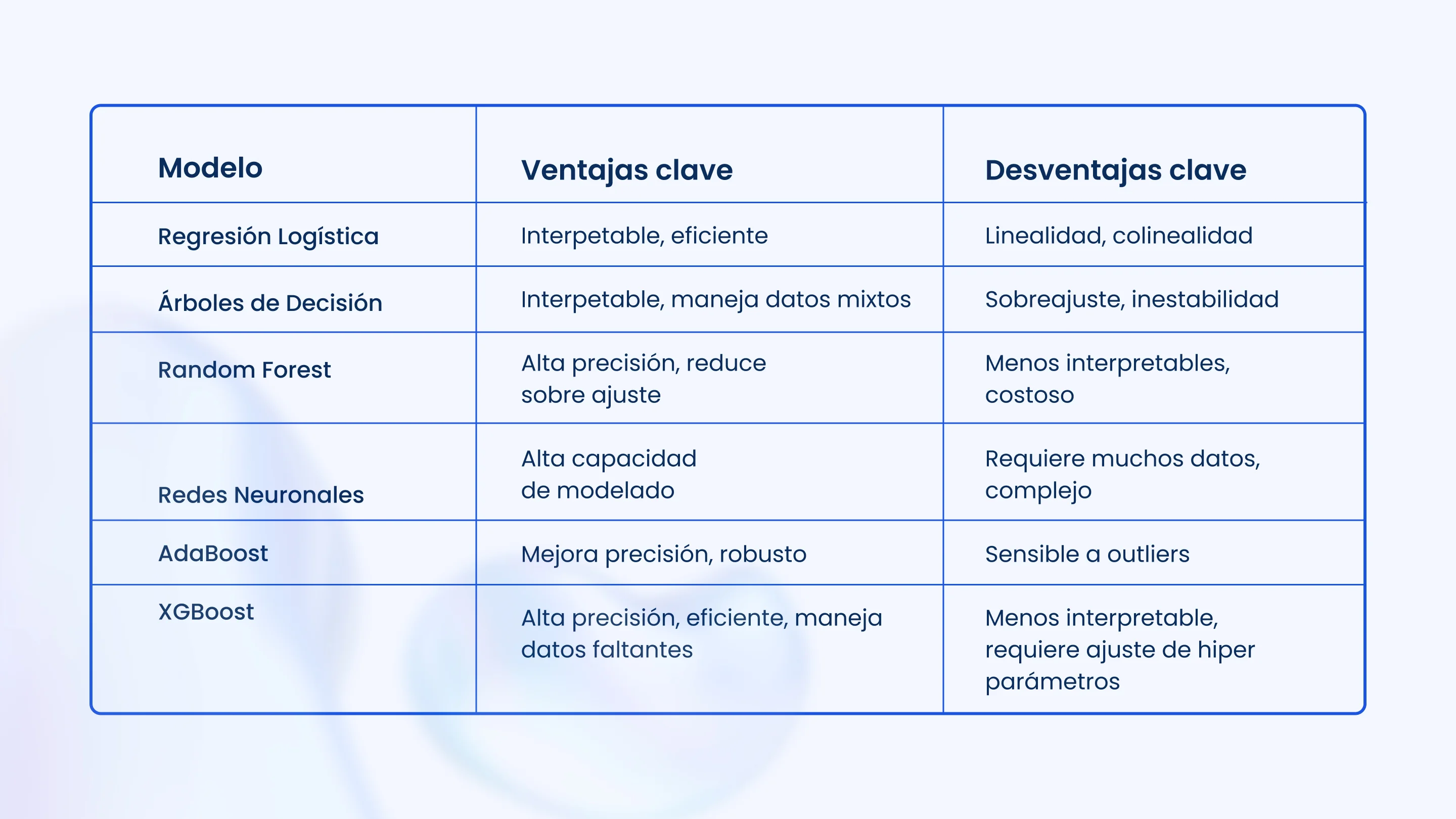
- Regresión logística: Si bien es un modelo lineal generalizado, su capacidad para estimar probabilidades de incumplimiento (por ejemplo, que un cliente pague un préstamo) la ha convertido en un punto de partida clásico. Es sencillo de interpretar pero asume una relación lineal entre las variables.
- Árboles de decisión: Ofrecen una alta interpretabilidad, crea una estructura en forma de árbol para tomar decisiones basadas en reglas. Son fáciles de visualizar y entender, pero pueden ser inestables ante pequeñas variaciones en los datos.
- Random forest: Este algoritmo, basado en el ensamble de múltiples árboles de decisión, mitiga el sobreajuste y mejora la precisión. Es versátil y puede manejar diferentes tipos de datos.
- Redes neuronales: Modelos multicapa que aprenden representaciones jerárquicas de los datos, ideales para resolver problemas complejos. No obstante, requieren grandes volúmenes de datos y su entrenamiento es computacionalmente costoso.
- AdaBoost: Este algoritmo de boosting crea un clasificador fuerte a partir de múltiples clasificadores débiles, asignando mayor peso a las observaciones mal clasificadas. Es sensible a los valores atípicos.
- XGBoost: Un algoritmo de boosting altamente eficiente y preciso que combina múltiples árboles de decisión. Es rápido, maneja datos faltantes y previene el sobreajuste con regularización. Aunque ofrece un gran rendimiento, puede ser menos interpretable y requiere ajuste cuidadoso de hiperparámetros.
La elección del modelo óptimo depende de la calidad y tamaño de los datos, la interpretabilidad requerida, la complejidad del problema y los recursos disponibles. No hay un modelo universalmente superior; debe evaluarse caso por caso. El pre procesamiento de datos es clave para el éxito del modelo. La evaluación se realiza con métricas de precisión, curva ROC, KS, recall y F1-score. La interpretabilidad con técnicas como SHAP y LIME ayudan a explicar modelos complejos. Información con base en Credit Risk Assessment based on Gradient Boosting Decision Tree.
La búsqueda de hiperparámetros es fundamental para optimizar el rendimiento de los modelos, ya que ajusta parámetros clave como la profundidad del árbol o la tasa de aprendizaje en algoritmos como Gradient Boosting. Técnicas como Grid Search, Random Search o la optimización bayesiana permiten explorar combinaciones óptimas de hiperparámetros.
Para garantizar la robustez del modelo, se utiliza la validación cruzada (cross-validation), dividiendo los datos en subconjuntos para entrenar y evaluar el modelo repetidamente, reduciendo el riesgo de overfitting. En contextos financieros, como la evaluación de riesgo crediticio, el backtesting es esencial para probar el desempeño del modelo en datos históricos, asegurando que sus predicciones sean confiables en escenarios reales.
Impacto del Machine Learning en la evaluación del riesgo crediticio y la calidad de datos
En conclusión, el machine learning ha transformado la evaluación del riesgo crediticio al proporcionar modelos para analizar grandes volúmenes de datos y descubrir patrones complejos. Estos modelos deben adaptarse continuamente para medir con precisión los posibles impagos, considerando el panorama externo, como circunstancias sociales, económicas y personales de los solicitantes. Es esencial prestar atención a la calidad de los datos, además, el uso de técnicas como el submuestreo y el sobremuestreo.
A medida que las nuevas técnicas de Machine Learning avanzan para minimizar el riesgo de fraude y el impago, es fundamental que estas soluciones se complementen con el conocimiento y la experiencia humana. La inteligencia artificial debe ser vista como una herramienta que, junto con el análisis crítico de datos, puede mejorar la toma de decisiones y beneficiar tanto a proveedores de servicios como a usuarios.
Conoce cómo la tecnología de finvero, a través de su plataforma de inteligencia artificial para la gestión crediticia, puede transformar tu empresa. Desde la solicitud hasta la cobranza, cubrimos todo el ciclo de vida del crédito utilizando datos tradicionales y alternativos. Descubre cómo nuestros modelos de machine learning pueden elevar tu tasa de aprobación de créditos y reducir los riesgos de fraude. ¡Contáctanos!
 Facebook
Facebook
 Linkedin
Linkedin
 Instagram
Instagram
 Whatsapp
Whatsapp